The security of data is an important and sensitive issue. It is also a multi-faceted subject, ranging from data integrity, to prevention of physical hostile actions.
This chapter describes the following security issues as addressed by Ovrimos:
Semantic Integrity in Ovrimos is obtained by defining and enforcing Integrity constraints. An integrity constraint is a conditional expression that is required not to evaluate to false.
The following integrity constraints are currently enforced by Ovrimos:
The following is a very simple example, of defining a domain and using this domain to constrain the values of a particular column of a table.
Example:
CREATE DOMAIN natural integer
check value > 0;
CREATE TABLE alpha (
...,
serial_number natural,
...
);
See also B.4.2.(Create Table in Ovrimos SQL).
Table constraints are defined as:
CHECK (conditional-expression)
These constraints are checked during insert and update statements.
Example:
CREATE TABLE alpha (
...,
payment integer,
commission integer,
...,
CHECK (commission < 0.15*payment)
);
The check constraint on insert and on update can only refer to the affected table rows, not to the whole table. In particular, the check expression should not refer to the table as a whole when its result depends on the row inserted or updated. At this point, it is not possible to make a SELECT in the same table where the INSERT or UPDATE is taking place.
See also B.4.2.(Create Table in Ovrimos SQL).
Ovrimos examines the row and allows insertion or update only when it complies to this rule.
Example:
CREATE TABLE alpha (
product_id integer PRIMARY KEY,
product_serial integer UNIQUE,
...
);
In the example above, the column product_id is the primary key, while column product_serial is a candidate key (because it is defined as unique).
See also B.4.2.(Create Table in Ovrimos SQL).
It is permitted to have NULL values in a foreign key (unless otherwise
specified at column definition). If any one component of a foreign key
is NULL, the entire foreign key is considered as NULL (i.e. it does not
reference a row in the referenced table).
Example:
CREATE TABLE beta (
...
main_product_id integer REFERENCES alpha(product_id),
...
);
The above main_product_id REFERENCES alpha(product_id)
is a shorthand for the statement:
main_product_id integer,
FOREIGN KEY (main_product_id)
REFERENCES alpha(product_id)
In the example above, column main_product_id is a foreign key that references product_id, the primary key of table alpha.
You can see more on table creation in the examples of section B.4.(Supported
SQL Statements.)
Finally, a few shortcomings on referential integrity:
There are no default values.
Foreign key constraints are now enforced only when INSERTing. One can
only insert a row when the primary key referenced exists in the primary table. No control
is exercised, though, when DELETE'ing or UPDATE'ing the primary key. This violates the
constraint that "all candidate keys referenced by a foreign key exist in the referred table".
This is a shortcoming expected to be removed in Ovrimos Gold release.
Example:
CREATE TABLE alpha (
...
product_name varchar(40) NOT NULL,
...
);
The above product_name varchar(40) NOT NULL is a shorthand for:
product_name varchar(40)
check (product_name is NOT NULL)
At creation time, column product_name is defined as NOT NULL. This column is not a candidate key. It is simply a column that should not contain NULL values (possibly due to application constraints).
Since having NULL values in this column violates the constraint, both insert and delete statements on the row are checked, to make sure the constraint is satisfied.
The notion of a transaction is extremely important in Ovrimos. All data manipulation and many data definition actions are executed in the environment of a transaction.
To get an idea of the benefits of a transaction, suppose we have the following simple scenario:
User U1 requests object A
User U1 updates object A
User U1 requests object B
User U1 updates object B
...
User U1 does not want the updates made thus far.
At this point, even if the user is alone, there is a problem. The user must undo all the updates made thus far. If the updates were made in the enveloping environment of a transaction, these updates would not be made permanent to the database, but they would be kept together as a unit. They would be made permanent when the user decided that the result was the desired. In this case, if the result is not the desired one, the user may use ROLLBACK and undo all the updates. If the result is the desired, COMMIT makes the updates permanent.
The situation is even more complicated if other users, running concurrently, have access to the same objects and make their own updates at the time. Whose updates would user U1 undo? What if another user deleted some of the objects U1 uses? What would the situation be should a power failure occur in the middle of such a complicated interaction?
Transactions are employed to alleviate some of these problems.
If a transaction T1 and a transaction T2 are running concurrently (i.e. there is interleaved execution of T1 and T2), these transactions are required to be serializable, in the sense that the result of running them concurrently must be the same as executing them one at a time. Since this requirement is very strict, there are options to loosen this restriction.
Even when transactions are employed, to guarantee atomicity, it is obvious that some kind of data locking is required for two reasons:
Ovrimos performs data locking at the row level, but there are many isolation levels, as we will see below. If no locking is done, three unwanted conditions may arise in the process of concurrent data access and modification by client requests.
Another transaction, T2, retrieves the updated row X.
T1 is rolled back and all its updates are canceled.
T2 has performed a Dirty Read, because it has retrieved something that does not exist.
Suppose there is a second transaction, T2, which updates this row and commits.
During the same transaction T1, the same row is retrieved, but with a different value. T1 has performed a Non-repeatable Read, since it fails to retrieve twice the same value from the row.
Suppose there is a second transaction, T2, which inserts a row, that also happens to satisfy the predicate used by T1.
T1 performs the same query and accesses a set of rows, which contains a row that was not there before.
Now T1 has read a Phantom.
To avoid all these abnormal situations, four isolation levels have been implemented, according to the SQL standard. These isolation levels are:
Each isolation level puts on transaction data interaction more severe restrictions than the previous one. The locking in Ovrimos is made on the table row level. There are two different kinds of locks:
Locks expire automatically at the end of the transaction.
The four isolation levels are achieved with the use of the locks in the following way:
For reading, no lock is required. Therefore, uncommitted objects are visible (dirty read).
For reading, a wait is required until no write-locks are held on the object. This ensures that no object, that is not yet committed, will be read. Thus, the Dirty Read is avoided. It is possible though to have a Non-repeatable Read.
For reading, a read-lock is required on the object. This ensures that repeated readings on the same object will bring the same value. Thus, the Non-repeatable Read is avoided.
Only the isolation level of the second transaction is considered, because in the discussion below, it is the one affected by the actions of the first. The dashed line indicates an idle (or blocked) transaction.
| Transaction T1 | Transaction T2 |
| START | |
| updates row | |
| ----- | START (READ UNCOMMITTED) |
| ----- | retrieves updated |
| rolls back | ----- |
Transaction T2 has read an (uncommitted) object which was rolled back, and in a sense never existed. This is a case of a Dirty Read.
When the Isolation Level is set to READ COMMITTED, a Dirty Read cannot occur, as the following examples indicate.
| Transaction T1 | Transaction T2 |
| START | |
| updates row | |
| ----- | START (READ COMMITTED) |
| blocks retrieving uncommitted objects | |
| rolls back | unblocks, retrieves old |
A write-lock is held on the updated object. Thus, T2 is blocked. As expected, by READ COMMITTED, when T1 rolled back, T2 read the old object.
| Transaction T1 | Transaction T2 |
| START | |
| updates row | |
| ----- | START (READ COMMITTED) |
| blocks retrieving uncommitted objects | |
| commits | unblocks, retrieves new |
A write-lock is held on the updated object. Thus, T2 is blocked. As expected by READ COMMITTED, when T1 committed, T2 read the new object.
Both REPEATABLE READ and SERIALIZABLE isolation levels perform correctly (since
their restrictions are more severe than READ COMMITTED).
Dirty Read is only one of the undesirable situations that may occur in a concurrent environment. Next, we address the Non-Repeatable Read case.
| Transaction T1 | Transaction T2 |
| START | |
| updates row | |
| ----- | START (READ UNCOMMITTED) |
| retrieves existing | |
| updates object | ----- |
| ----- | retrieves new |
Since T2 read different data from the same object during the same transaction, we have a case of Non-Repeatable read.
| Transaction T1 | Transaction T2 |
| ----- | START (READ COMMITTED) |
| retrieves existing | |
| updates | ----- |
| ----- | blocks retrieving uncommitted objects |
| commits | unblocks, retrieves new |
| Transaction T1 | Transaction T2 |
| ----- | START (READ COMMITTED) |
| retrieves existing | |
| updates | ----- |
| ----- | blocks retrieving uncommitted objects |
| rolls back | unblocks, retrieves old |
In the cases above, when T1 committed, there was a case of Non-repeatable Read, while when T1 rolled back, there was no such occurrence. This is not desirable. The following example is a case of Repeatable Read.
| Transaction T1 | Transaction T2 |
| ----- | START (REPEATABLE READ) |
| retrieves existing | |
| blocks updating | ----- |
| unblocks and updates | commits/rolls back |
When, T2 runs in Isolation Level REPEATABLE READ, it places a write-lock, which blocks other transactions from accessing objects, used by T2.
Obviously, when T2 is run in Isolation Level SERIALIZABLE, which puts more severe restrictions on concurrency, there can be no case of Non-repeatable read.
The following is an example of phantom row appearance.
| Transaction T1 | Transaction T2 |
| ----- | START (READ UNCOMMITTED) |
| retrieves existing rows | |
| inserts new row | ----- |
| ----- | retrieves rows+new row |
Transaction T2 has read a row that did not exist before.
| Transaction T1 | Transaction T2 |
| ----- | START (READ COMMITTED) |
| retrieves existing rows | |
| inserts new row | ----- |
| ----- | blocks retrieving uncommitted objects |
| commits | unblocks and retrieves rows+new row |
| or rolls back | unblocks and retrieves rows |
| without old row |
Depending on the final action of T1 (commit or Roll back), T2 either retreats a row that did not exist before or does not.
| Transaction T1 | Transaction T2 |
| ----- | START (REPEATABLE READ) |
| retrieves existing rows | |
| inserts new row | ----- |
| ----- | retrieves old rows without new row |
| commits | ----- |
| ----- | retrieves old rows+new row |
Even REPEATABLE READ is not enough to prevent the phantom appearance. In the example above, T2 does not see the phantom row until T1 commits, but eventually, it does retrieve data that did not exist before.
| Transaction T1 | Transaction T2 |
| ----- | START (SERIALIZABLE) |
| retrieves existing rows | |
| inserts new row | ----- |
| ----- | retrieves old rows without new row |
| commits | ----- |
| ----- | retrievies old rows without new row |
All three possible concurrency anomalies are removed when the SERIALIZABLE Isolation Level is set.
The server mechanism for acquiring and releasing locks during a transaction has a growing phase, where it acquires locks and a shrinking phase, where it releases locks. During the growing phase, no locks are released. This is equivalent to the two-phase locking protocol.
Ovrimos examines the lock requests, depending on the prevailing conditions. If it is not possible to grant a lock immediately, the request is not rejected at once. Instead, a wait indication is placed in the waiting queue with the hope that the other short transactions will commit their actions and release the requested objects.
When locks are used, another undesirable situation may arise, deadlock. A deadlock is a cycle of interdependencies, produced when a connection holds some objects and waits for a requested object, which may be locked by another connection. Although a deadlock is not a violation of data integrity, it is a detrimental situation and has to be prevented.
In order to prevent a deadlock , a graph of interdependencies is created, which is checked every time a request is candidate for the waiting list. If the insertion results in a cycle, then the request is immediately rejected.
Anyway, a request for wait may not be served for a long time if the other transactions do not release the locked objects.
Transactions are executed under the following rules:
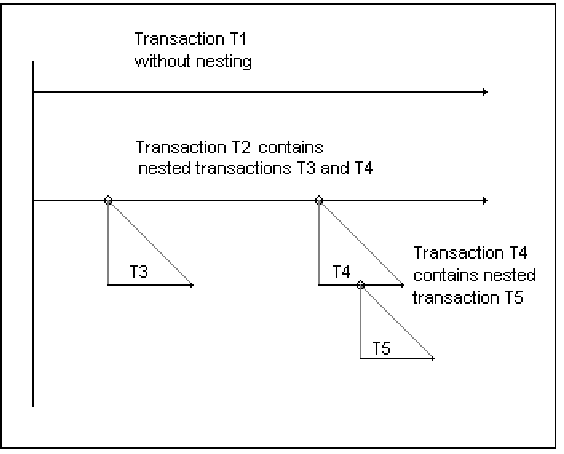
Picture 13.1 shows the transaction nesting.
The pseudocode below describes the nesting.
T1 is an example of a transaction without nesting. T2, which contains nested transactions, may be described by the following pseudocode:
Start T2
...
Statements of T2
...
Start T3
...
Statements of T3
...
Commit T3
Start T4
...
Statements of T4
...
Start T5
...
Commit T5
...
Commit T4
...
Commit T2
The nested transaction mechanism is implemented internally, but it is not yet available to the user through the existing SQL Terminal interface. It may be used in SQL Query Tool by the (undocumented) Nest statement. It is possible to use nesting in C and C++ applications through the Ovrimos C, C++ library. You may contact support@ovrimos.com for more information.
The log is used to record all actions performed to the database. Actions recorded on the log are based on transactions. The beginning and end points of a transaction, as well as the actions on the database objects, are recorded on the log and used for a possible rolling back of open transactions.
The log is particularly useful when on-line backup is taken. Since a previous backup exists and the log is always updated by Ovrimos, it is possible to take a backup at any time without halting the database. The previous backup and the log will be used in combination if data recovery is required.
It is strongly recommended to take frequent backups. We also advise users to keep their log and backup directories on a separate volume.
See also 12.(Database Maintenance).
Extra protection, through data encryption, is offered to Ovrimos database managers for each database separately, at creation time. If users opt for encrypting the database, they may choose an encryption algorithm and they must supply the name of a binary file that holds at least the number of bytes required for the key. It is best to specify a file on removable media (diskette, tape, etc), that can be safekept elsewhere after database loading. The key must be supplied every time the database is started.
The parameters defined in database creation are mentioned in 4.(Database Manager). There is also a description of parameter CIPHER in A.2.2.(Database Parameters).
Encryption algorithms used by this version are:
An example of a cipher value is:
CIPHER=nullcipher.dll nullcipher
See more about defining and using ciphers in E.1.(User-provided ciphers).
There is little chance that someone will find the BLOB address by trying URLs at random, since the BLOB URL is based on a random number from 1 to 232-1.
The Database Manager user, is a person with Database Management privileges. There is only one such user for all Ovrimos databases in one installation. This is user dbman. User dbman may create and delete databases. This user may also edit database parameters.
User dbman is authenticated through the use of a password.
The dbman password is initially
pass .
We strongly recommend that
you change this password the first time you log into the Database Manager.
The maximum length of the dbman password is 60 characters.
See more about the Database Manager in chapter 4.(The Database Manager).
The other category of Ovrimos users are database users. Each database has an administrator with full privileges over all database objects. This is user admin. User admin may create other database users and has authority over these users. The database administrator may be different from the Database Manager. The administrator of one Ovrimos database is not necessarily the administrator of another Ovrimos database.
For every database created, there is always a user admin, with full privileges and a user public, without password, with minimal privileges. Other users, created with administrator privileges, have privilege over data not users.
User public is created without a password and is not allowed to log in. For the use of public, see 13.4.5.(Privilege Inheritance).
Users may change their password (provided that this is
permitted by the $USERPOLICY), using the following statement:
UPDATE USER username WITH 'new-password';
Example:
UPDATE USER admin WITH 'nebula';
As always, the password is case sensitive.
It is also possible to update the password with NULL, in which case the user may no longer login to the database, until a new password is assigned to him/her. The administrator may use a full version of the update command which is:
UPDATE USER identifier [FOR 'user name']
[WITH 'password'][LIKE identifier]
[USING 'attribute=value;attribute=value;...'];
Passwords are strings of alphanumeric characters. The maximum length of a password is 89 characters.
Every user, except admin is allowed to update only his/her own password. Even this is not always the case, as we will immediately see. Ovrimos enforces a password policy, to allow a certain degree of password protection. The password policy is set at creation time and at any other time, when required, by dbman (the user who creates and edits the database). Restrictions, currently enforced on passwords may be any of the following:
Parameter USERPOLICY, set by dbman, holds all information about user passwords. All users except admin are subject to USERPOLICY.
User admin may by-pass these rules and set his/her own password as well as other users' passwords regardless of the existing USERPOLICY. Ovrimos issues warning messages, when the rules are broken, but accepts the administrator's updates, nevertheless.
See A.2.2.(Database Parameters) and 4.(The Database Manager). For more information about setting password policy.
Also, user dbman, who is not a database user, is not subject to the rules of password policy.
Ovrimos sends the following two mail messages to the administrator's specified mailbox address (see also MAILBOX) in case of failed logins:
Privileges on database objects are granted to users through the Grant SQL statement and revoked through the Revoke SQL statement.
In the case of privileges, database objects are tables and views (treated as tables) and table columns, while privileges are the privilege to select from a table and delete from a table, to insert data into the table columns, to update all or particular columns of a table and to modify foreign keys.
Privileges may be granted with a grant option, in which case the user may grant them to other users. See more on Grant and Revoke in B.4.(Supported SQL Statements).
Administration of users in Ovrimos databases is performed with simple statements. One extra feature, found in Ovrimos SQL, is the option of Privilege Inheritance. Specific users can be designated as prototype users, typically with a NULL password that disallows logging in. Users created LIKE this user, inherit his/her privileges. This makes it easy to administer privileges for groups of people with a simple grant/revoke to/from the prototype user. This hierarchy can be extended to as many levels as we wish. In the future, multiple inheritance will allow the SQL3 "roles" to be implemented. Following are the user administration statements:
Other users may be created with the following statement:
CREATE USER username FOR 'Full Name' WITH 'user password';
Example:
CREATE USER mary FOR 'Mary' WITH 'xyz123';
Full syntax is:
CREATE USER username FOR 'full name'
with 'password'|NULL [like prototype-user]
[USING 'attribute=value;...'];
Example:
CREATE USER mary FOR 'Mary' WITH 'xyz123'
LIKE john USING 'mailbox=Mary@xyzzy.com';
In this case, user mary has inherited all privileges from user john.
User public may be granted with a certain 'typical' set of privileges that will normally be granted to many users. User public will then be used as follows:
Example:
GRANT Select, Delete, ... ON TABLE tabname
TO PUBLIC;
... Other grant statements.
CREATE USER Kendal FOR 'Kendal Eridani'
WITH 'xyz' LIKE public;
It is also possible to create a user LIKE admin. This user has administrative privileges on database objects, not on database users. Thus, only admin may create, update or drop other users.
In tandem with modern application demands and offerings in cryptographic technology, Ovrimos comes with support for Public-Key Infrastructure:
Of course, no system is fail-safe if human factors are not taken into account. Users must be familiar with the Certificate Manager and follow the proper procedures. See more about certificates in 4.5.
If your organization wishes to issue certificates, without requesting the services of specialized outside organizations such as Verisign, Thawte, Bellsign etc., it should create a local certification authority, (LCA for short) .
If the certificates it issues are not only for internal use within the organization, a self-signed LCA is probably all that is needed. In such cases all parties involved in secure communications with Ovrimos should be configured to trust this LCA. Of course, a server certificate issued by a self-signed LCA would be quite inapropriate for a Web site for the general public such as an e-commerce Web site. Since the self-signed LCA will not be trusted outside the organization, Web browsers will not be able to verify the identity of the Web site.
Another solution, probably the most cost effective, would be to buy a certificate for the Web server signed by a globally trusted external CA, such as Verisign, Thawte, Belsign etc., and use a self-signed LCA for all internal host and client certificates. If you want some user certificates to be trusted outside your organization you can always purchase them seperately by a globally trusted External Certification Authority (ECA for short) .
The fact that an ECA has a good reputation and many products, such as Web browsers, are preconfigured to trust it, does not imply you should trust it within your organization. In some situations you should not.
Another option you have for your LCA, is to have it signed by a globally trusted ECA. Servers machines and personal certificates signed by the LCA will be trusted by the general public. However, internally, in your organization, you may still choose to trust only your LCA and not its signer, which means that you are not putting any part of your internal security infrastructure in the hands of the external CA.
Finally, you should note that you can have more than one LCA. For example, you may create an LCA, which in turn will sign you other LCAs. Big CAs do exactly that. This enables them to use the secondary LCAs for every day signing operations while the private key of the primary LCA is only used once or twice a year.
There is a problem with describing security-related software, as it is not necessarily used by security experts. Setting up and managing an Public-Key Infrastructure is a very sensitive duty. While Certificate Manager makes certain tasks easy for the security conscious system administrator, who is not necessarily a security expert, that does not imply that Certificate Manager is enough in security sensitive installations. We have given some possible scenarios which a security conscious system administrator may consider for setting up a Public Key Infrastructure (PKI for short). However, one should not be misled into thinking that because the most powerful computers of intelligence agencies can not break the kind of cryptography supported by Ovrimos, that by installink a PKI, they prevent a teenage hacker breaking into their systems taking advantage of well-known security holes or an employee taking advantage of a colleague's lunch break to use their computer and authorization to obtain sensitive information or make changes to some database. Security experts can advise not only on how to best utilize a PKI, but also how to avoid traditional attacks. If your data is sensitive, you need their expertise, more than you need a 4096 bit private key.